Tutorial: Retrieval-Augmented Generation (RAG)¶
Let's walk through a quick example of basic question answering with and without retrieval-augmented generation (RAG) in DSPy. Specifically, let's build a system for answering Tech questions, e.g. about Linux or iPhone apps.
Install the latest DSPy via pip install -U dspy and follow along. If you're looking instead for a conceptual overview of DSPy, this recent lecture is a good place to start. You also need to run pip install datasets. This tutorial uses dspy.Embedder and dspy.retrievers.Embeddings, which require numpy: pip install dspy[numpy].
Configuring the DSPy environment.¶
Let's tell DSPy that we will use OpenAI's gpt-4o-mini in our modules. To authenticate, DSPy will look into your OPENAI_API_KEY. You can easily swap this out for other providers or local models.
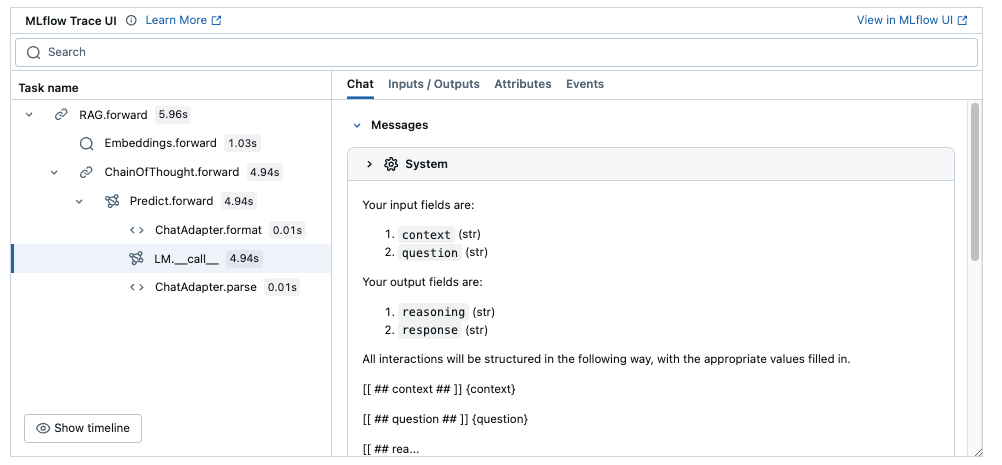
Recommended: Set up MLflow Tracing to understand what's happening under the hood.
MLflow DSPy Integration¶
MLflow is an LLMOps tool that natively integrates with DSPy and offer explainability and experiment tracking. In this tutorial, you can use MLflow to visualize prompts and optimization progress as traces to understand the DSPy's behavior better. You can set up MLflow easily by following the four steps below.
- Install MLflow
%pip install mlflow>=2.20
- Start MLflow UI in a separate terminal
mlflow ui --port 5000
- Connect the notebook to MLflow
import mlflow
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("DSPy")
- Enabling tracing.
mlflow.dspy.autolog()
Once you have completed the steps above, you can see traces for each program execution on the notebook. They provide great visibility into the model's behavior and helps you understand the DSPy's concepts better throughout the tutorial.
To kearn more about the integration, visit MLflow DSPy Documentation as well.
import dspy
lm = dspy.LM('openai/gpt-4o-mini')
dspy.configure(lm=lm)
Exploring some basic DSPy Modules.¶
You can always prompt the LM directly via lm(prompt="prompt") or lm(messages=[...]). However, DSPy gives you Modules as a better way to define your LM functions.
The simplest module is dspy.Predict. It takes a DSPy Signature, i.e. a structured input/output schema, and gives you back a callable function for the behavior you specified. Let's use the "in-line" notation for signatures to declare a module that takes a question (of type str) as input and produces a response as an output.
qa = dspy.Predict('question: str -> response: str')
response = qa(question="what are high memory and low memory on linux?")
print(response.response)
In Linux, "high memory" and "low memory" refer to different regions of the system's memory address space, particularly in the context of 32-bit architectures. - **Low Memory**: This typically refers to the memory that is directly accessible by the kernel. In a 32-bit system, this is usually the first 896 MB of RAM (from 0 to 896 MB). The kernel can directly map this memory, making it faster for the kernel to access and manage. Low memory is used for kernel data structures and for user processes that require direct access to memory. - **High Memory**: This refers to the memory above the low memory limit, which is not directly accessible by the kernel in a 32-bit system. This area is typically above 896 MB. The kernel cannot directly access this memory without using special mechanisms, such as mapping it into the kernel's address space when needed. High memory is used for user processes that require more memory than what is available in low memory. In summary, low memory is directly accessible by the kernel, while high memory requires additional steps for the kernel to access it, especially in 32-bit systems. In 64-bit systems, this distinction is less significant as the kernel can address a much larger memory space directly.
Notice how the variable names we specified in the signature defined our input and output argument names and their role.
Now, what did DSPy do to build this qa module? Nothing fancy in this example, yet. The module passed your signature, LM, and inputs to an Adapter, which is a layer that handles structuring the inputs and parsing structured outputs to fit your signature.
Let's see it directly. You can inspect the n last prompts sent by DSPy easily. Alternatively, if you enabled MLflow Tracing above, you can see the full LLM interactions for each program execution in a tree view.
dspy.inspect_history(n=1)
[2024-11-23T23:16:35.966534] System message: Your input fields are: 1. `question` (str) Your output fields are: 1. `response` (str) All interactions will be structured in the following way, with the appropriate values filled in. [[ ## question ## ]] {question} [[ ## response ## ]] {response} [[ ## completed ## ]] In adhering to this structure, your objective is: Given the fields `question`, produce the fields `response`. User message: [[ ## question ## ]] what are high memory and low memory on linux? Respond with the corresponding output fields, starting with the field `[[ ## response ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`. Response: [[ ## response ## ]] In Linux, "high memory" and "low memory" refer to different regions of the system's memory address space, particularly in the context of 32-bit architectures. - **Low Memory**: This typically refers to the memory that is directly accessible by the kernel. In a 32-bit system, this is usually the first 896 MB of RAM (from 0 to 896 MB). The kernel can directly map this memory, making it faster for the kernel to access and manage. Low memory is used for kernel data structures and for user processes that require direct access to memory. - **High Memory**: This refers to the memory above the low memory limit, which is not directly accessible by the kernel in a 32-bit system. This area is typically above 896 MB. The kernel cannot directly access this memory without using special mechanisms, such as mapping it into the kernel's address space when needed. High memory is used for user processes that require more memory than what is available in low memory. In summary, low memory is directly accessible by the kernel, while high memory requires additional steps for the kernel to access it, especially in 32-bit systems. In 64-bit systems, this distinction is less significant as the kernel can address a much larger memory space directly. [[ ## completed ## ]]
DSPy has various built-in modules, e.g. dspy.ChainOfThought, dspy.ProgramOfThought, and dspy.ReAct. These are interchangeable with basic dspy.Predict: they take your signature, which is specific to your task, and they apply general-purpose prompting techniques and inference-time strategies to it.
For example, dspy.ChainOfThought is an easy way to elicit reasoning out of your LM before it commits to the outputs requested in your signature.
In the example below, we'll omit str types (as the default type is string). You should feel free to experiment with other fields and types, e.g. try topics: list[str] or is_realistic: bool.
cot = dspy.ChainOfThought('question -> response')
cot(question="should curly braces appear on their own line?")
Prediction(
reasoning='The placement of curly braces on their own line depends on the coding style and conventions being followed. In some programming languages and style guides, such as the Allman style, curly braces are placed on their own line to enhance readability. In contrast, other styles, like K&R style, place the opening brace on the same line as the control statement. Ultimately, it is a matter of personal or team preference, and consistency within a project is key.',
response='Curly braces can appear on their own line depending on the coding style you are following. If you prefer a style that enhances readability, such as the Allman style, then yes, they should be on their own line. However, if you are following a different style, like K&R, they may not need to be. Consistency is important, so choose a style and stick with it.'
)
Interestingly, asking for reasoning can make the output response shorter in this case. Is this a good thing or a bad thing? It depends on what you need: there's no free lunch, but DSPy gives you the tools to experiment with different strategies extremely quickly.
By the way, dspy.ChainOfThought is implemented in DSPy, using dspy.Predict. This is a good place to dspy.inspect_history if you're curious.
Using DSPy well involves evaluation and iterative development.¶
You already know a lot about DSPy at this point. If all you want is quick scripting, this much of DSPy already enables a lot. Sprinkling DSPy signatures and modules into your Python control flow is a pretty ergonomic way to just get stuff done with LMs.
That said, you're likely here because you want to build a high-quality system and improve it over time. The way to do that in DSPy is to iterate fast by evaluating the quality of your system and using DSPy's powerful tools, e.g. Optimizers.
Manipulating Examples in DSPy.¶
To measure the quality of your DSPy system, you need (1) a bunch of input values, like questions for example, and (2) a metric that can score the quality of an output from your system. Metrics vary widely. Some metrics need ground-truth labels of ideal outputs, e.g. for classification or question answering. Other metrics are self-supervised, e.g. checking faithfulness or lack of hallucination, perhaps using a DSPy program as a judge of these qualities.
Let's load a dataset of questions and their (pretty long) gold answers. Since we started this notebook with the goal of building a system for answering Tech questions, we obtained a bunch of StackExchange-based questions and their correct answers from the RAG-QA Arena dataset.
import orjson
from dspy.utils import download
# Download question--answer pairs from the RAG-QA Arena "Tech" dataset.
download("https://huggingface.co/dspy/cache/resolve/main/ragqa_arena_tech_examples.jsonl")
with open("ragqa_arena_tech_examples.jsonl") as f:
data = [orjson.loads(line) for line in f]
# Inspect one datapoint.
data[0]
{'question': 'why igp is used in mpls?',
'response': "An IGP exchanges routing prefixes between gateways/routers. \nWithout a routing protocol, you'd have to configure each route on every router and you'd have no dynamic updates when routes change because of link failures. \nFuthermore, within an MPLS network, an IGP is vital for advertising the internal topology and ensuring connectivity for MP-BGP inside the network.",
'gold_doc_ids': [2822, 2823]}
Given a simple dict like this, let's create a list of dspy.Examples, which is the datatype that carries training (or test) datapoints in DSPy.
When you build a dspy.Example, you should generally specify .with_inputs("field1", "field2", ...) to indicate which fields are inputs. The other fields are treated as labels or metadata.
data = [dspy.Example(**d).with_inputs('question') for d in data]
# Let's pick an `example` here from the data.
example = data[2]
example
Example({'question': 'why are my text messages coming up as maybe?', 'response': 'This is part of the Proactivity features new with iOS 9: It looks at info in emails to see if anyone with this number sent you an email and if it finds the phone number associated with a contact from your email, it will show you "Maybe". \n\nHowever, it has been suggested there is a bug in iOS 11.2 that can result in "Maybe" being displayed even when "Find Contacts in Other Apps" is disabled.', 'gold_doc_ids': [3956, 3957, 8034]}) (input_keys={'question'})
Now, let's divide the data into:
Training (and with it Validation) set:
- These are the splits you typically give to DSPy optimizers.
- Optimizers typically learn directly from the training examples and check their progress using the validation examples.
- It's good to have 30--300 examples for training and validation each.
- For prompt optimizers in particular, it's often better to pass more validation than training.
- Below, we'll use 200 in total. MIPROv2 will split them into 20% training and 80% validation if you don't pass a valset.
Development and Test sets: The rest, typically on the order of 30--1000, can be used for:
- development (i.e., you can inspect them as you iterate on your system) and
- testing (final held-out evaluation).
import random
random.Random(0).shuffle(data)
trainset, devset, testset = data[:200], data[200:500], data[500:1000]
len(trainset), len(devset), len(testset)
(200, 300, 500)
Evaluation in DSPy.¶
What kind of metric can suit our question-answering task? There are many choices, but since the answers are long, we may ask: How well does the system response cover all key facts in the gold response? And the other way around, how well is the system response not saying things that aren't in the gold response?
That metric is essentially a semantic F1, so let's load a SemanticF1 metric from DSPy. This metric is actually implemented as a very simple DSPy module using whatever LM we're working with.
from dspy.evaluate import SemanticF1
# Instantiate the metric.
metric = SemanticF1(decompositional=True)
# Produce a prediction from our `cot` module, using the `example` above as input.
pred = cot(**example.inputs())
# Compute the metric score for the prediction.
score = metric(example, pred)
print(f"Question: \t {example.question}\n")
print(f"Gold Response: \t {example.response}\n")
print(f"Predicted Response: \t {pred.response}\n")
print(f"Semantic F1 Score: {score:.2f}")
Question: why are my text messages coming up as maybe? Gold Response: This is part of the Proactivity features new with iOS 9: It looks at info in emails to see if anyone with this number sent you an email and if it finds the phone number associated with a contact from your email, it will show you "Maybe". However, it has been suggested there is a bug in iOS 11.2 that can result in "Maybe" being displayed even when "Find Contacts in Other Apps" is disabled. Predicted Response: Your text messages are showing up as "maybe" because your messaging app is uncertain about the sender's identity. This typically occurs when the sender's number is not saved in your contacts or if the message is from an unknown number. To resolve this, you can save the contact in your address book or check the message settings in your app. Semantic F1 Score: 0.33
The final DSPy module call above actually happens inside metric. You might be curious how it measured the semantic F1 for this example.
dspy.inspect_history(n=1)
[2024-11-23T23:16:36.149518] System message: Your input fields are: 1. `question` (str) 2. `ground_truth` (str) 3. `system_response` (str) Your output fields are: 1. `reasoning` (str) 2. `ground_truth_key_ideas` (str): enumeration of key ideas in the ground truth 3. `system_response_key_ideas` (str): enumeration of key ideas in the system response 4. `discussion` (str): discussion of the overlap between ground truth and system response 5. `recall` (float): fraction (out of 1.0) of ground truth covered by the system response 6. `precision` (float): fraction (out of 1.0) of system response covered by the ground truth All interactions will be structured in the following way, with the appropriate values filled in. [[ ## question ## ]] {question} [[ ## ground_truth ## ]] {ground_truth} [[ ## system_response ## ]] {system_response} [[ ## reasoning ## ]] {reasoning} [[ ## ground_truth_key_ideas ## ]] {ground_truth_key_ideas} [[ ## system_response_key_ideas ## ]] {system_response_key_ideas} [[ ## discussion ## ]] {discussion} [[ ## recall ## ]] {recall} # note: the value you produce must be a single float value [[ ## precision ## ]] {precision} # note: the value you produce must be a single float value [[ ## completed ## ]] In adhering to this structure, your objective is: Compare a system's response to the ground truth to compute recall and precision of key ideas. You will first enumerate key ideas in each response, discuss their overlap, and then report recall and precision. User message: [[ ## question ## ]] why are my text messages coming up as maybe? [[ ## ground_truth ## ]] This is part of the Proactivity features new with iOS 9: It looks at info in emails to see if anyone with this number sent you an email and if it finds the phone number associated with a contact from your email, it will show you "Maybe". However, it has been suggested there is a bug in iOS 11.2 that can result in "Maybe" being displayed even when "Find Contacts in Other Apps" is disabled. [[ ## system_response ## ]] Your text messages are showing up as "maybe" because your messaging app is uncertain about the sender's identity. This typically occurs when the sender's number is not saved in your contacts or if the message is from an unknown number. To resolve this, you can save the contact in your address book or check the message settings in your app. Respond with the corresponding output fields, starting with the field `[[ ## reasoning ## ]]`, then `[[ ## ground_truth_key_ideas ## ]]`, then `[[ ## system_response_key_ideas ## ]]`, then `[[ ## discussion ## ]]`, then `[[ ## recall ## ]]` (must be formatted as a valid Python float), then `[[ ## precision ## ]]` (must be formatted as a valid Python float), and then ending with the marker for `[[ ## completed ## ]]`. Response: [[ ## reasoning ## ]] The system response provides a general explanation for why text messages may show up as "maybe," focusing on the uncertainty of the sender's identity. However, it does not mention the specific iOS features or the potential bug in iOS 11.2 that are highlighted in the ground truth. The ground truth explains that this feature is part of iOS 9's Proactivity features and mentions a specific bug in iOS 11.2, which is not addressed in the system response. [[ ## ground_truth_key_ideas ## ]] 1. Proactivity features introduced in iOS 9. 2. The system checks emails to associate phone numbers with contacts. 3. "Maybe" is displayed if the number is not saved in contacts. 4. Mention of a bug in iOS 11.2 causing "Maybe" to appear incorrectly. [[ ## system_response_key_ideas ## ]] 1. Text messages show up as "maybe" due to uncertainty about the sender's identity. 2. Occurs when the sender's number is not saved in contacts or is from an unknown number. 3. Suggests saving the contact or checking message settings. [[ ## discussion ## ]] There is some overlap between the ground truth and the system response regarding the uncertainty of the sender's identity and the suggestion to save the contact. However, the system response lacks specific details about the iOS features and the bug mentioned in the ground truth. The ground truth provides a more comprehensive explanation of the "maybe" feature, while the system response is more general and does not address the iOS version specifics. [[ ## recall ## ]] 0.25 [[ ## precision ## ]] 0.5 [[ ## completed ## ]]
For evaluation, you could use the metric above in a simple loop and just average the score. But for nice parallelism and utilities, we can rely on dspy.Evaluate.
# Define an evaluator that we can re-use.
evaluate = dspy.Evaluate(devset=devset, metric=metric, num_threads=24,
display_progress=True, display_table=2)
# Evaluate the Chain-of-Thought program.
evaluate(cot)
Average Metric: 125.68 / 300 (41.9%): 100%|██████████| 300/300 [00:00<00:00, 666.96it/s]
2024/11/23 23:16:36 INFO dspy.evaluate.evaluate: Average Metric: 125.68228336477591 / 300 (41.9%)
| question | example_response | gold_doc_ids | reasoning | pred_response | SemanticF1 | |
|---|---|---|---|---|---|---|
| 0 | when to use c over c++, and c++ over c? | If you are equally familiar with both C++ and C, it's advisable to... | [733] | C and C++ are both powerful programming languages, but they serve ... | Use C when you need low-level access to memory, require high perfo... | |
| 1 | should images be stored in a git repository? | One viewpoint expresses that there is no significant downside, esp... | [6253, 6254, 6275, 6278, 8215] | Storing images in a Git repository can be beneficial for version c... | Images can be stored in a Git repository, but it's important to co... | ✔️ [0.444] |
41.89
Tracking Evaluation Results in MLflow Experiment
To track and visualize the evaluation results over time, you can record the results in MLflow Experiment.
import mlflow
with mlflow.start_run(run_name="rag_evaluation"):
evaluate = dspy.Evaluate(
devset=devset,
metric=metric,
num_threads=24,
display_progress=True,
)
# Evaluate the program as usual
result = evaluate(cot)
# Log the aggregated score
mlflow.log_metric("semantic_f1_score", result.score)
# Log the detailed evaluation results as a table
mlflow.log_table(
{
"Question": [example.question for example in eval_set],
"Gold Response": [example.response for example in eval_set],
"Predicted Response": [output[1] for output in result.results],
"Semantic F1 Score": [output[2] for output in result.results],
},
artifact_file="eval_results.json",
)
To learn more about the integration, visit MLflow DSPy Documentation as well.
So far, we built a very simple chain-of-thought module for question answering and evaluated it on a small dataset.
Can we do better? In the rest of this guide, we will build a retrieval-augmented generation (RAG) program in DSPy for the same task. We'll see how this can boost the score substantially, then we'll use one of the DSPy Optimizers to compile our RAG program to higher-quality prompts, raising our scores even more.
Basic Retrieval-Augmented Generation (RAG).¶
First, let's download the corpus data that we will use for RAG search. An older version of this tutorial used the full (650,000 document) corpus. To make this very fast and cheap to run, we've downsampled the corpus to just 28,000 documents.
download("https://huggingface.co/dspy/cache/resolve/main/ragqa_arena_tech_corpus.jsonl")
Set up your system's retriever.¶
As far as DSPy is concerned, you can plug in any Python code for calling tools or retrievers. Here, we'll just use OpenAI Embeddings and do top-K search locally, just for convenience.
Note: The step below will require that you either do pip install -U faiss-cpu or pass brute_force_threshold=30_000 to dspy.retrievers.Embeddings to avoid faiss.
# %pip install -U faiss-cpu # or faiss-gpu if you have a GPU
max_characters = 6000 # for truncating >99th percentile of documents
topk_docs_to_retrieve = 5 # number of documents to retrieve per search query
with open("ragqa_arena_tech_corpus.jsonl") as f:
corpus = [orjson.loads(line)['text'][:max_characters] for line in f]
print(f"Loaded {len(corpus)} documents. Will encode them below.")
embedder = dspy.Embedder('openai/text-embedding-3-small', dimensions=512)
search = dspy.retrievers.Embeddings(embedder=embedder, corpus=corpus, k=topk_docs_to_retrieve)
Loaded 28436 documents. Will encode them below. Training a 32-byte FAISS index with 337 partitions, based on 28436 x 512-dim embeddings
Build your first RAG Module.¶
In the previous guide, we looked at individual DSPy modules in isolation, e.g. dspy.Predict("question -> answer").
What if we want to build a DSPy program that has multiple steps? The syntax below with dspy.Module allows you to connect a few pieces together, in this case, our retriever and a generation module, so the whole system can be optimized.
Concretely, in the __init__ method, you declare any sub-module you'll need, which in this case is just a dspy.ChainOfThought('context, question -> response') module that takes retrieved context, a question, and produces a response. In the forward method, you simply express any Python control flow you like, possibly using your modules. In this case, we first invoke the search function defined earlier and then invoke the self.respond ChainOfThought module.
class RAG(dspy.Module):
def __init__(self):
self.respond = dspy.ChainOfThought('context, question -> response')
def forward(self, question):
context = search(question).passages
return self.respond(context=context, question=question)
Let's use the RAG module.
rag = RAG()
rag(question="what are high memory and low memory on linux?")
Prediction(
reasoning="High Memory and Low Memory in Linux refer to two segments of the kernel's memory space. Low Memory is the portion of memory that the kernel can access directly and is statically mapped at boot time. This area is typically used for kernel data structures and is always accessible to the kernel. High Memory, on the other hand, is not permanently mapped in the kernel's address space, meaning that the kernel cannot access it directly without first mapping it into its address space. High Memory is used for user-space applications and temporary data buffers. The distinction allows for better memory management and security, as user-space applications cannot directly access kernel-space memory.",
response="In Linux, High Memory refers to the segment of memory that is not permanently mapped in the kernel's address space, which means the kernel must map it temporarily to access it. This area is typically used for user-space applications and temporary data buffers. Low Memory, in contrast, is the portion of memory that the kernel can access directly and is statically mapped at boot time. It is used for kernel data structures and is always accessible to the kernel. This separation enhances security by preventing user-space applications from accessing kernel-space memory directly."
)
dspy.inspect_history()
[2024-11-23T23:16:49.175612] System message: Your input fields are: 1. `context` (str) 2. `question` (str) Your output fields are: 1. `reasoning` (str) 2. `response` (str) All interactions will be structured in the following way, with the appropriate values filled in. [[ ## context ## ]] {context} [[ ## question ## ]] {question} [[ ## reasoning ## ]] {reasoning} [[ ## response ## ]] {response} [[ ## completed ## ]] In adhering to this structure, your objective is: Given the fields `context`, `question`, produce the fields `response`. User message: [[ ## context ## ]] [1] «As far as I remember, High Memory is used for application space and Low Memory for the kernel. Advantage is that (user-space) applications cant access kernel-space memory.» [2] «HIGHMEM is a range of kernels memory space, but it is NOT memory you access but its a place where you put what you want to access. A typical 32bit Linux virtual memory map is like: 0x00000000-0xbfffffff: user process (3GB) 0xc0000000-0xffffffff: kernel space (1GB) (CPU-specific vector and whatsoever are ignored here). Linux splits the 1GB kernel space into 2 pieces, LOWMEM and HIGHMEM. The split varies from installation to installation. If an installation chooses, say, 512MB-512MB for LOW and HIGH mems, the 512MB LOWMEM (0xc0000000-0xdfffffff) is statically mapped at the kernel boot time; usually the first so many bytes of the physical memory is used for this so that virtual and physical addresses in this range have a constant offset of, say, 0xc0000000. On the other hand, the latter 512MB (HIGHMEM) has no static mapping (although you could leave pages semi-permanently mapped there, but you must do so explicitly in your driver code). Instead, pages are temporarily mapped and unmapped here so that virtual and physical addresses in this range have no consistent mapping. Typical uses of HIGHMEM include single-time data buffers.» [3] «This is relevant to the Linux kernel; Im not sure how any Unix kernel handles this. The High Memory is the segment of memory that user-space programs can address. It cannot touch Low Memory. Low Memory is the segment of memory that the Linux kernel can address directly. If the kernel must access High Memory, it has to map it into its own address space first. There was a patch introduced recently that lets you control where the segment is. The tradeoff is that you can take addressable memory away from user space so that the kernel can have more memory that it does not have to map before using. Additional resources: http://tldp.org/HOWTO/KernelAnalysis-HOWTO-7.html http://linux-mm.org/HighMemory» [4] «The first reference to turn to is Linux Device Drivers (available both online and in book form), particularly chapter 15 which has a section on the topic. In an ideal world, every system component would be able to map all the memory it ever needs to access. And this is the case for processes on Linux and most operating systems: a 32-bit process can only access a little less than 2^32 bytes of virtual memory (in fact about 3GB on a typical Linux 32-bit architecture). It gets difficult for the kernel, which needs to be able to map the full memory of the process whose system call its executing, plus the whole physical memory, plus any other memory-mapped hardware device. So when a 32-bit kernel needs to map more than 4GB of memory, it must be compiled with high memory support. High memory is memory which is not permanently mapped in the kernels address space. (Low memory is the opposite: it is always mapped, so you can access it in the kernel simply by dereferencing a pointer.) When you access high memory from kernel code, you need to call kmap first, to obtain a pointer from a page data structure (struct page). Calling kmap works whether the page is in high or low memory. There is also kmap_atomic which has added constraints but is more efficient on multiprocessor machines because it uses finer-grained locking. The pointer obtained through kmap is a resource: it uses up address space. Once youve finished with it, you must call kunmap (or kunmap_atomic) to free that resource; then the pointer is no longer valid, and the contents of the page cant be accessed until you call kmap again.» [5] «/proc/meminfo will tell you how free works, but /proc/kcore can tell you what the kernel uses. From the same page: /proc/kcore This file represents the physical memory of the system and is stored in the ELF core file format. With this pseudo-file, and an unstripped kernel (/usr/src/linux/vmlinux) binary, GDB can be used to examine the current state of any kernel data structures. The total length of the file is the size of physical memory (RAM) plus 4KB. /proc/meminfo This file reports statistics about memory usage on the system. It is used by free(1) to report the amount of free and used memory (both physical and swap) on the system as well as the shared memory and buffers used by the kernel. Each line of the file consists of a parameter name, followed by a colon, the value of the parameter, and an option unit of measurement (e.g., kB). The list below describes the parameter names and the format specifier required to read the field value. Except as noted below, all of the fields have been present since at least Linux 2.6.0. Some fields are displayed only if the kernel was configured with various options; those dependencies are noted in the list. MemTotal %lu Total usable RAM (i.e., physical RAM minus a few reserved bits and the kernel binary code). MemFree %lu The sum of LowFree+HighFree. Buffers %lu Relatively temporary storage for raw disk blocks that shouldnt get tremendously large (20MB or so). Cached %lu In-memory cache for files read from the disk (the page cache). Doesnt include SwapCached. SwapCached %lu Memory that once was swapped out, is swapped back in but still also is in the swap file. (If memory pressure is high, these pages dont need to be swapped out again because they are already in the swap file. This saves I/O.) Active %lu Memory that has been used more recently and usually not reclaimed unless absolutely necessary. Inactive %lu Memory which has been less recently used. It is more eligible to be reclaimed for other purposes. Active(anon) %lu (since Linux 2.6.28) [To be documented.] Inactive(anon) %lu (since Linux 2.6.28) [To be documented.] Active(file) %lu (since Linux 2.6.28) [To be documented.] Inactive(file) %lu (since Linux 2.6.28) [To be documented.] Unevictable %lu (since Linux 2.6.28) (From Linux 2.6.28 to 2.6.30, CONFIG_UNEVICTABLE_LRU was required.) [To be documented.] Mlocked %lu (since Linux 2.6.28) (From Linux 2.6.28 to 2.6.30, CONFIG_UNEVICTABLE_LRU was required.) [To be documented.] HighTotal %lu (Starting with Linux 2.6.19, CONFIG_HIGHMEM is required.) Total amount of highmem. Highmem is all memory above ~860MB of physical memory. Highmem areas are for use by user-space programs, or for the page cache. The kernel must use tricks to access this memory, making it slower to access than lowmem. HighFree %lu (Starting with Linux 2.6.19, CONFIG_HIGHMEM is required.) Amount of free highmem. LowTotal %lu (Starting with Linux 2.6.19, CONFIG_HIGHMEM is required.) Total amount of lowmem. Lowmem is memory which can be used for everything that highmem can be used for, but it is also available for the kernels use for its own data structures. Among many other things, it is where everything from Slab is allocated. Bad things happen when you're out of lowmem. LowFree %lu (Starting with Linux 2.6.19, CONFIG_HIGHMEM is required.) Amount of free lowmem. MmapCopy %lu (since Linux 2.6.29) (CONFIG_MMU is required.) [To be documented.] SwapTotal %lu Total amount of swap space available. SwapFree %lu Amount of swap space that is currently unused. Dirty %lu Memory which is waiting to get written back to the disk. Writeback %lu Memory which is actively being written back to the disk. AnonPages %lu (since Linux 2.6.18) Non-file backed pages mapped into user-space page tables. Mapped %lu Files which have been mapped, such as libraries. Shmem %lu (since Linux 2.6.32) [To be documented.] Slab %lu In-kernel data structures cache. SReclaimable %lu (since Linux 2.6.19) Part of Slab, that might be reclaimed, such as caches. SUnreclaim %lu (since Linux 2.6.19) Part of Slab, that cannot be reclaimed on memory pressure. KernelStack %lu (since Linux 2.6.32) Amount of memory allocated to kernel stacks. PageTables %lu (since Linux 2.6.18) Amount of memory dedicated to the lowest level of page tables. Quicklists %lu (since Linux 2.6.27) (CONFIG_QUICKLIST is required.) [To be documented.] NFS_Unstable %lu (since Linux 2.6.18) NFS pages sent to the server, but not yet committed to stable storage. Bounce %lu (since Linux 2.6.18) Memory used for block device bounce buffers. WritebackTmp %lu (since Linux 2.6.26) Memory used by FUSE for temporary writeback buffers. CommitLimit %lu (since Linux 2.6.10) Based on the overcommit ratio (vm.overcommit_ratio), this is the total amount of memory currently available to be allocated on the system. This limit is adhered to only if strict overcommit accounting is enabled (mode 2 in /proc/sys/vm/overcommit_ratio). The CommitLimit is calculated using the following formula: CommitLimit = ([total RAM pages] - [total huge TLB pages]) * overcommit_ratio / 100 + [total swap pages] For example, on a system with 1GB of physical RAM and 7GB of swap with a overcommit_ratio of 30, this formula yields a CommitLimit of 7.3GB. For more details, see the memory overcommit documentation in the kernel source file Documentation/vm/overcommit-accounting. Committed_AS %lu The amount of memory presently allocated on the system. The committed memory is a sum of all of the memory which has been allocated by processes, even if it has not been used by them as of yet. A process which allocates 1GB of memory (using malloc(3) or similar), but touches only 300MB of that memory will show up as using only 300MB of memory even if it has the address space allocated for the entire 1GB. This 1GB is memory which has been committed to by the VM and can be used at any time by the allocating application. With strict overcommit enabled on the system (mode 2 /proc/sys/vm/overcommit_memory), allocations w» [[ ## question ## ]] what are high memory and low memory on linux? Respond with the corresponding output fields, starting with the field `[[ ## reasoning ## ]]`, then `[[ ## response ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`. Response: [[ ## reasoning ## ]] High Memory and Low Memory in Linux refer to two segments of the kernel's memory space. Low Memory is the portion of memory that the kernel can access directly and is statically mapped at boot time. This area is typically used for kernel data structures and is always accessible to the kernel. High Memory, on the other hand, is not permanently mapped in the kernel's address space, meaning that the kernel cannot access it directly without first mapping it into its address space. High Memory is used for user-space applications and temporary data buffers. The distinction allows for better memory management and security, as user-space applications cannot directly access kernel-space memory. [[ ## response ## ]] In Linux, High Memory refers to the segment of memory that is not permanently mapped in the kernel's address space, which means the kernel must map it temporarily to access it. This area is typically used for user-space applications and temporary data buffers. Low Memory, in contrast, is the portion of memory that the kernel can access directly and is statically mapped at boot time. It is used for kernel data structures and is always accessible to the kernel. This separation enhances security by preventing user-space applications from accessing kernel-space memory directly. [[ ## completed ## ]]
Earlier with a CoT module, we got around 40% in terms of semantic F1 on our devset. Would this RAG module score better?
evaluate(RAG())
Average Metric: 166.54 / 300 (55.5%): 100%|██████████| 300/300 [00:04<00:00, 61.40it/s]
2024/11/23 23:16:54 INFO dspy.evaluate.evaluate: Average Metric: 166.53601368289284 / 300 (55.5%)
| question | example_response | gold_doc_ids | reasoning | pred_response | SemanticF1 | |
|---|---|---|---|---|---|---|
| 0 | when to use c over c++, and c++ over c? | If you are equally familiar with both C++ and C, it's advisable to... | [733] | C should be used over C++ primarily in scenarios where simplicity ... | Use C over C++ when working on embedded systems, requiring low-lev... | ✔️ [0.500] |
| 1 | should images be stored in a git repository? | One viewpoint expresses that there is no significant downside, esp... | [6253, 6254, 6275, 6278, 8215] | Storing images in a Git repository is generally not recommended du... | While it is technically possible to store images in a Git reposito... | ✔️ [0.444] |
55.51
Using a DSPy Optimizer to improve your RAG prompt.¶
Off the shelf, our RAG module scores 55%. What are our options to make it stronger? One of the various choices DSPy offers is optimizing the prompts in our pipeline.
If there are many sub-modules in your program, all of them will be optimized together. In this case, there's only one: self.respond = dspy.ChainOfThought('context, question -> response')
Let's set up and use DSPy's MIPRO (v2) optimizer. The run below has a cost around $1.5 (for the medium auto setting) and may take some 20-30 minutes depending on your number of threads.
tp = dspy.MIPROv2(metric=metric, auto="medium", num_threads=24) # use fewer threads if your rate limit is small
optimized_rag = tp.compile(RAG(), trainset=trainset,
max_bootstrapped_demos=2, max_labeled_demos=2)
The prompt optimization process here is pretty systematic, you can learn about it for example in this paper. Importantly, it's not a magic button. It's very possible that it can overfit your training set for instance and not generalize well to a held-out set, making it essential that we iteratively validate our programs.
Let's check on an example here, asking the same question to the baseline rag = RAG() program, which was not optimized, and to the optimized_rag = MIPROv2(..)(..) program, after prompt optimization.
baseline = rag(question="cmd+tab does not work on hidden or minimized windows")
print(baseline.response)
You are correct that cmd+tab does not work on hidden or minimized windows. To switch back to a minimized app, you must first switch to another application and let it take focus before returning to the minimized one.
pred = optimized_rag(question="cmd+tab does not work on hidden or minimized windows")
print(pred.response)
The Command + Tab shortcut on macOS is designed to switch between currently open applications, but it does not directly restore minimized or hidden windows. When you use Command + Tab, it cycles through the applications that are actively running, and minimized windows do not count as active. To manage minimized windows, you can use other shortcuts or methods. For example, you can use Command + Option + H + M to hide all other applications and minimize the most recently used one. Alternatively, you can navigate to the application you want to restore using Command + Tab and then manually click on the minimized window in the Dock to bring it back to focus.
You can use dspy.inspect_history(n=2) to view the RAG prompt before optimization and after optimization.
Concretely, in one of the runs of this notebook, the optimized prompt does the following (note that it may be different on a later rerun).
- Constructs the following instruction,
Using the provided `context` and `question`, analyze the information step by step to generate a comprehensive and informative `response`. Ensure that the response clearly explains the concepts involved, highlights key distinctions, and addresses any complexities noted in the context.
- And includes two fully worked out RAG examples with synthetic reasoning and answers, e.g.
how to transfer whatsapp voice message to computer?.
Let's now evaluate on the overall devset.
evaluate(optimized_rag)
Average Metric: 183.32 / 300 (61.1%): 100%|██████████| 300/300 [00:02<00:00, 104.48it/s]
2024/11/23 23:17:21 INFO dspy.evaluate.evaluate: Average Metric: 183.3194433591069 / 300 (61.1%)
| question | example_response | gold_doc_ids | reasoning | pred_response | SemanticF1 | |
|---|---|---|---|---|---|---|
| 0 | when to use c over c++, and c++ over c? | If you are equally familiar with both C++ and C, it's advisable to... | [733] | The context provides insights into the strengths and weaknesses of... | You should consider using C over C++ in scenarios where simplicity... | ✔️ [0.333] |
| 1 | should images be stored in a git repository? | One viewpoint expresses that there is no significant downside, esp... | [6253, 6254, 6275, 6278, 8215] | The context discusses the challenges and considerations of storing... | Storing images in a Git repository is generally considered bad pra... | ✔️ [0.500] |
61.11
Keeping an eye on cost.¶
DSPy allows you to track the cost of your programs, which can be used to monitor the cost of your calls. Here, we'll show you how to track the cost of your programs with DSPy.
cost = sum([x['cost'] for x in lm.history if x['cost'] is not None]) # in USD, as calculated by LiteLLM for certain providers
Saving and loading.¶
The optimized program has a pretty simple structure on the inside. Feel free to explore it.
Here, we'll save optimized_rag so we can load it again later without having to optimize from scratch.
optimized_rag.save("optimized_rag.json")
loaded_rag = RAG()
loaded_rag.load("optimized_rag.json")
loaded_rag(question="cmd+tab does not work on hidden or minimized windows")
Prediction(
reasoning='The context explains how the Command + Tab shortcut functions on macOS, particularly in relation to switching between applications. It notes that this shortcut does not bring back minimized or hidden windows directly. Instead, it cycles through applications that are currently open and visible. The information also suggests alternative methods for managing minimized windows and provides insights into how to navigate between applications effectively.',
response='The Command + Tab shortcut on macOS is designed to switch between currently open applications, but it does not directly restore minimized or hidden windows. When you use Command + Tab, it cycles through the applications that are actively running, and minimized windows do not count as active. To manage minimized windows, you can use other shortcuts or methods. For example, you can use Command + Option + H + M to hide all other applications and minimize the most recently used one. Alternatively, you can navigate to the application you want to restore using Command + Tab and then manually click on the minimized window in the Dock to bring it back to focus.'
)
Saving programs in MLflow Experiment
Instead of saving the program to a local file, you can track it in MLflow for better reproducibility and collaboration.
- Dependency Management: MLflow automatically save the frozen environment metadata along with the program to ensure reproducibility.
- Experiment Tracking: With MLflow, you can track the program's performance and cost along with the program itself.
- Collaboration: You can share the program and results with your team members by sharing the MLflow experiment.
To save the program in MLflow, run the following code:
import mlflow
# Start an MLflow Run and save the program
with mlflow.start_run(run_name="optimized_rag"):
model_info = mlflow.dspy.log_model(
optimized_rag,
artifact_path="model", # Any name to save the program in MLflow
)
# Load the program back from MLflow
loaded = mlflow.dspy.load_model(model_info.model_uri)
To learn more about the integration, visit MLflow DSPy Documentation as well.
What's next?¶
Improving from around 42% to approximately 61% on this task, in terms of SemanticF1, was pretty easy.
But DSPy gives you paths to continue iterating on the quality of your system and we have barely scratched the surface.
In general, you have the following tools:
- Explore better system architectures for your program, e.g. what if we ask the LM to generate search queries for the retriever? See, e.g., the STORM pipeline built in DSPy.
- Explore different prompt optimizers or weight optimizers. See the Optimizers Docs.
- Scale inference time compute using DSPy Optimizers, e.g. via ensembling multiple post-optimization programs.
- Cut cost by distilling to a smaller LM, via prompt or weight optimization.
How do you decide which ones to proceed with first?
The first step is to look at your system outputs, which will allow you to identify the sources of lower performance if any. While doing all of this, make sure you continue to refine your metric, e.g. by optimizing against your judgments, and to collect more (or more realistic) data, e.g. from related domains or from putting a demo of your system in front of users.